Continuing work on my AI chatbot.
Using Cursor today, I read a developer’s post on rudimentary AI use and am trying his workflow out. I had a previous bad experience with Cursor but today;s experience was 1000% better. Compared to Aider (taking a sledgehammer to pastry), Cursor is much more like a scalpel these days, which I greatly prefer!
I loaded my chatbot code from previous, and asked it to review the existing code. Then gave it a few prompts to add a new feature to the chatbot, which it did.
I spent the rest of the time wrangling python libs and updating langchain and updating the code to use the latest version of langchain.
One observation is that this is muddying up documentation (it is all lagging behind code, which developers are plowing ahead with but no one can really keep up with a large codebase if the documentation is lagging, which means we have to read it or load it into an LLM to tease out what information we need).
Technical non-hands on leadership will insist on purist coding to qualify entry to their teams, but developers will need to rely on LLMs to help them understand the codebase, which is a bit of a paradox.
Locking things down, trying to figure out where and how to store my embedding vectorstore so an LLM can use it to chat with my vectorstore about me.
Considerations: 1. Your Vectorstore is Private by Default The FAISS index is just a set of embeddings and metadata, stored as files. Unless you upload these files to a public location or send their contents to a third-party API, they are private. When you use them in AWS Lambda, as long as you don’t send the raw content or embeddings to an external service, they remain private. 2. How LLMs Get Trained LLMs (like OpenAI’s GPT) are only trained on data that is: Publicly available on the internet, or Explicitly submitted to them for training (e.g., via API with opt-in for training). OpenAI, Anthropic, and most reputable providers do NOT train on your API data by default. OpenAI’s data usage policy: “We do not use data submitted by customers via our API to train OpenAI models or improve OpenAI’s service offering.” 3. Best Practices to Keep Your Data Private Do not upload your vectorstore to any public repository or bucket. Use a private S3 bucket with strict IAM permissions. Do not send your raw document content or embeddings to any third-party API unless you trust their privacy policy. When using LLM APIs (like OpenAI): Only send the user’s query and the relevant context (retrieved chunks), not your entire vectorstore. This is standard RAG (Retrieval-Augmented Generation) practice. 4. AWS-Specific Tips S3 buckets are private by default. Only grant access to your Lambda function’s IAM role. Enable S3 server-side encryption for extra security. Use VPC endpoints if you want to restrict S3 access to your AWS network. 5. What NOT to Do Do not upload your vectorstore to a public S3 bucket or public GitHub repo. Do not send your entire vectorstore or all your document content to an LLM API.
Summary Table
|---------------------------------------|-------|-----------------------------------------------|
| Action | Safe? | Notes |
|---|---|---|
| Store vectorstore in private S3 bucket | ✅ | Only accessible to you/Lambda |
| Send user query + context to LLM API | ✅ | Standard RAG, not used for training by default |
| Upload vectorstore to public repo | ❌ | Anyone can access |
| Send all embeddings/content to LLM API | ❌ | Not needed, increases risk |
Anyway, back to chatbot.
- ✅ Have LLM come up with a UI for me. Manually tweak if necessary.
- ✅ Refactor to pull all styling into a .css file
- ✅ Create a backend to handle the chatbot requests and responses.
- ✅ LLM to create a standard python module content ingestor to:
- track rebuild time in a json file (will rebuild only the timestamp is after rebuild time stored)
- extract text from a mdx, md or pdf file
- load files as documents for embeddings
- ✅ create a python service module to:
- load the documents embeddings vectorstore using FAISS through iteration
- query the vectorstore for relevant documents based on user input
- ✅ Test this whole stack of modules and code
- ✅ talk to LLM about how best to store this vectorstore embeddings so it stays private and secure:
- ❌ Solution:
- I will use aws cli to upload it to aws s3, closed bucket access with the exception of a specified aws lambdafunction
- i will use the vectorstore in the lambda function to query it and return results to the user
- configure aws iam permissions for aws lambda and aws s3
- create aws lambda layers for the python libs i need that aws does not have and configure it in IaC for deployment
- ✅convert python query code to FastAPI/Mangum so it can be uploaded to aws lambda
- ✅test FastAPI code
- deploy the FastAPI code to AWS Lambda using AWS SAM or Serverless Framework
- deploy the lambda function using aws cli
- configure chatbot UI to query aws lambda function for user input, secured using API Gateway with API tokens issued
- use AWS Secrets Manager to store sensitive information like API keys and access tokens
This is a great opportunity to pick up Terraform as well. This is literally endless learning but here we go.
Terraform Tutorial
Inspired tutorial terraform basic flow
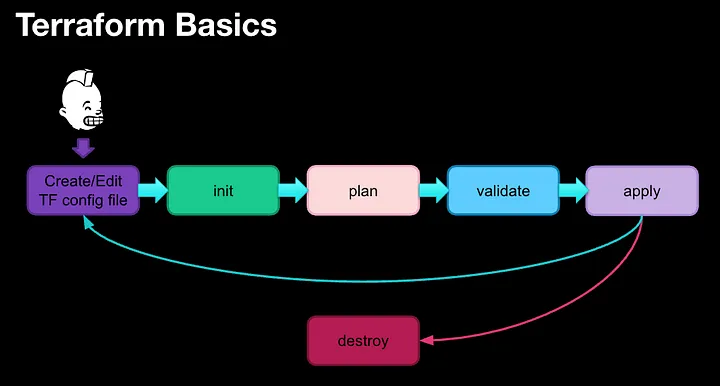{kind=link}
- Installing Terraform
brew tap hashicorp/tap brew install hashicorp/tap/terraform - apparently, i needed to upgrade my command line tools amd here is to hoping it doesn’t wreck my current setup.
sudo rm -rf /Library/Developer/CommandLineTools sudo xcode-select --install
3. Add Terraform to ~/.zshrc
terraform -install-autocomplete4. Invoke Docker from command line: open -a Docker
5. Tutorial summary steps:
# Create a new directory for your Terraform project
# create a .tf file
# write in that file
terraform init
terraform apply
docker ps
terraform destroyOMG. I love it. so much better than Docker! and my bash scripts to set up and take down! 6. Going through AWS tutorial
- will need terraform cli installed, aws cli installed, aws account with associated credentials
# Create a new directory for your Terraform project
mkdir terraform-aws-example
cd terraform-aws-example
# Create a main.tf file with the following content
touch main.tf
# had to pull an ami id from aws
terraform init
terraform fmt
terraform validate
vi main.tf
aws ssm get-parameters --names /aws/service/ami-amazon-linux-latest/amzn2-ami-hvm-x86_64-gp2 --region us-east-1
terraform apply
terraform show
terraform state list
terraform destroy7. Using AWS SSM for free secret storing services:
pip install mangum
pip freeze > requirements.txt
aws ssm put-parameter --name "<path>" --value "<value>" --type "SecureString"
aws ssm describe-parameters --query "Parameters[*].Name"8. AWS SAM local build:
sam build --use-container
sam local invoke --event event.json9. There are two ways (free!) that we can store and access our vectors:
- use a vector database, Pinecone
pip install pinecone- store the vectors in a file, in aws s3, that aws lambda downloads in its /tmp dir as needed. but this is a bad idea because it will try to download it or, we have to implement some caching strategy
- store the vectors as an encrypted aws lambda layer (<250mb) that we can access from our lambda function)
cd backend
mkdir -p python/faiss_index
cp faiss_index/* python/faiss_index/
zip -r chatbot_faiss_layer.zip python10. Decision: I will implement the first version as a aws lambda layer, then I will implement it to pull from Pinecone.